Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents

Abstract
Large language model (LLM) agents have shown great potential in solving real-world software engineering (SWE) problems. The most advanced open-source SWE agent framework can resolve over 27% of real GitHub issues in SWE-Bench Lite. However, these sophisticated agent frameworks exhibit varying strengths, excelling in certain tasks while underperforming in others. To fully harness the diversity of these agents, we propose DEI (Diversity Empowered Intelligence), a framework that leverages their unique expertise. DEI functions as a meta-module atop existing SWE agent frameworks, managing agent collectives for enhanced problem-solving. Experimental results show that a DEI-guided committee of agents is able to surpass the best individual agent's performance by a large margin. For instance, a collection of open-source SWE agents with a maximum individual performance of 27.3% on SWE-Bench Lite can be boosted to 34.3% by DEI, beating most closed-source solutions on the leaderboard. Our findings contribute to the growing body of research on collaborative AI systems and their potential to solve complex software engineering challenges.
SWE-Bench Lite Leaderboard Results
(Last Updated: 2024-08-12)
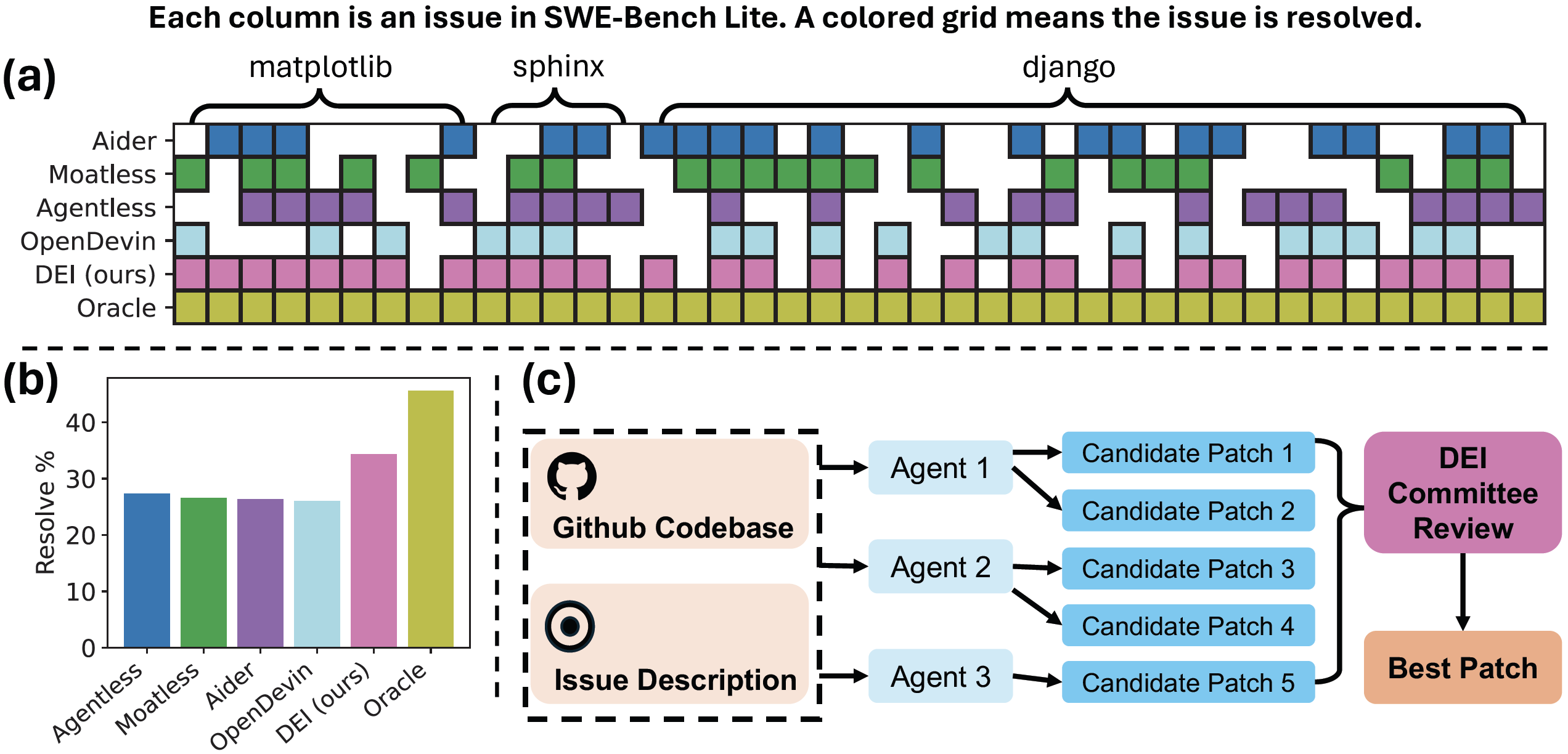
We present the resolve rates of top-ranking submissions on SWE-Bench Lite. We evaluate 3 DEI Committees formed by different groups of agents. Each DEI Committee outperforms the best agent in it. DEIBASE-Open, a committee formed by 4 open-source agents can beat many closed-source agents.
| DEI Group | % Resolve | SWE Agent System | Open Source Code | Trajectories | Open Patch Candidates | Backend LLM |
|---|---|---|---|---|---|---|
| 1 | 55.0 | Salesforce Research DEIBASE-1 | ✓ | ✓ | ✗ | gpt4o |
| 1 | 50.6 | Cosine Genie | ✗ | ✗ | - | Fine-tuned OpenAI GPT |
| 1 | 43.0 | CodeStory Aide | ✗ | ✗ | - | gpt4o + Claude 3.5 Sonnet |
| - | 38.0 | AbenteAI MentatBot | ✗ | ✗ | - | gpt4o |
| 2 | 37 | Salesforce Research DEIBASE-2 | ✓ | ✓ | ✗ | gpt4o |
| Open | 34.3 | Salesforce Research DEI-Open | ✓ | ✓ | ✓ | gpt4o |
| - | 34.0 | Bytedance MarsCode | ✗ | ✗ | - | gpt4o |
| - | 33.0 | Alibaba Lingma | ✗1 | ✗ | - | gpt-4-1106-preview |
| 2 | 31.3 | Factory Code Droid | ✗ | ✗ | - | Anthropic + OpenAI |
| 2 | 30.6 | AutoCodeRover | ✗2 | ✗ | - | gpt4o |
| 2 | 29.6 | Amazon Q Developer | ✗ | ✗ | - | Unknown |
| 2 | 28.3 | CodeR | ✗1 | ✗ | - | gpt-4-1106-preview |
| 2 | 28.0 | MASAI | ✗1 | ✗ | - | Unknown |
| - | 27.6 | SIMA | ✗1 | ✓ | ✓3 | gpt4o |
| Open | 27.3 | Agentless | ✓ | ✓ | - | gpt4o |
| Open | 26.6 | Moatless Tools | ✓ | ✓ | - | Claude 3.5 Sonnet |
| - | 26.6 | IBM Research Agent | ✗ | ✗ | - | Unknown |
| Open | 26.3 | Aider | ✓ | ✗ | - | gpt4o + Claude 3 Opus |
| Open | 26.0 | OpenDevin + CodeAct | ✓ | ✓ | - | gpt4o |
Note:
- 1 Their repo has no code yet.
- 2 An earlier version is open-source. The current one is not.
- 3 Candidates are generated by a "modification of moatless tools".
DEIBASE: A Simple Yet Powerful DEI framework
We present DEIBASE, a simple yet powerful implementation of the DEI framework, tailored for SWE-Bench like problems. The context in the setup includes the repository, along with relevant files and issue descriptions. The meta-policy's action space consists of the final patches generated by different agent frameworks, each specialized in addressing various aspects of the problem.
DEIBASE utilizes a Large Language Model (LLM) as a code review committee. The LLM evaluates candidate patches by analyzing the state of the code base before and after the proposed changes, in conjunction with the contextual information from the issue descriptions. It produces detailed explanations for each patch, justifying the modifications based on the identified issues, the context, and the specific changes made.
While other methods of code review and scoring, such as rule-based approaches, can be incorporated into our framework, the use of an LLM-based committee offers a unique advantage. LLMs excel at evaluating solutions, which often requires less complexity than generating them. DEIBASE thus serves as an effective baseline for LLM-based SWE evaluation, highlighting potential performance variations among diverse SWE agents and showcasing the capabilities of our method.
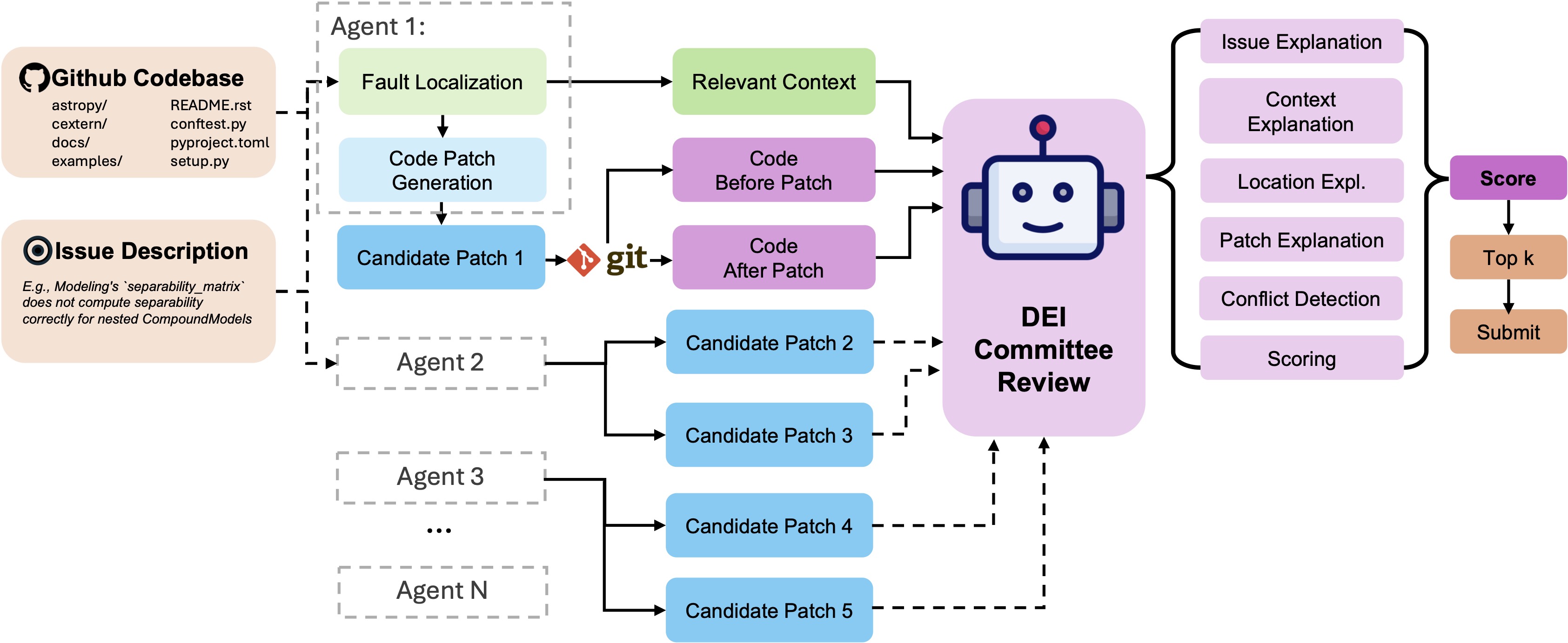
Step 1: Input Construction
Four inputs are given to DEIBASE for each patch: the issue description itself, relevant context (code snippets identified by an SWE agent as relevant to the issue), code before the patch, and code after the patch. The form of inputs reflects two design choices. First, the entire repository is often too large to fit directly in the context limit of LLMs, so we use the relevant context instead to save token costs and help the model focus. Second, the format of a patch is not the easiest for an LLM to read as it switches back and forth between the pre-change code and the changed code, so we give the code before and after the patch separately to the model for easier understanding.
Step 2: Explanation Generation
To help the model better "understand" the patch before scoring, we instruct it to generate various explanations regarding the patch in a specified order. The order is decided so that the earlier explanations can also help the later ones. We describe each explanation in the order they are generated here:
- Issue explanation: Explains what the issue is about and what problem it may be causing.
- Context explanation: Explains how and why each relevant code span (there might be many of these) is relevant to the issue.
- Location explanation: Explains if and why the patch is modifying the correct part of the code that's faulty.
- Patch explanation: Explains if and how the patch is fixing the issue.
- Conflict detection: Checks whether the patch conflicts with other relevant code snippets.
We explicitly instruct the model to refer back to the earlier explanations while generating the later ones.
Step 3: Patch Scoring
Based on its own explanations, the model is asked to give the candidate patch a score of 1 to 10. We give the model detailed rubrics of what violations/mistakes lead to higher score deduction and what should only be considered minor violations. For example, if the model finds the modification location to be wrong, it is considered a serious mistake.
Experiments
We aim to answer two research questions with our experiments: 1) How diverse are LLM-based SWE agents in terms of intra- and inter-agent diversity? 2) To what extent can DEI harness the diversity and increase the performances of these SWE agents?
Experiment Setup
Benchmark and Agents
Benchmark: We conduct our experiments on SWE-Bench Lite, a 300-instance subset sampled from the full SWE-Bench for providing a more self-contained evaluation of functional bug fixes. Compared to the full SWE-Bench, SWE-Bench Lite has significantly more submissions on the leaderboard for us to conduct a more comprehensive analysis of inter-agent diversity.
Agents: For intra-agent diversity, we consider three well-performing open-source agents on the SWE-Bench Lite leaderboard: Agentless, Moatless, and Aider by running them 10 times with the same parameters. For inter-agent diversity, we consider 10 agents (open-source or not) that have similar resolve rates, all between 26.0% and 31.0% on the leaderboard by directly using their submitted patches to the SWE-Bench issues.
For the evaluation of DEIBASE on different agents, we consider 3 groups of agents that form different DEI Committees, including one group consisting of only open-source agents. For the evaluation of DEIBASE on multiple runs of a single agent, we use the generations of the three aforementioned agents -- Agentless, Moatless Tools, and Aider.
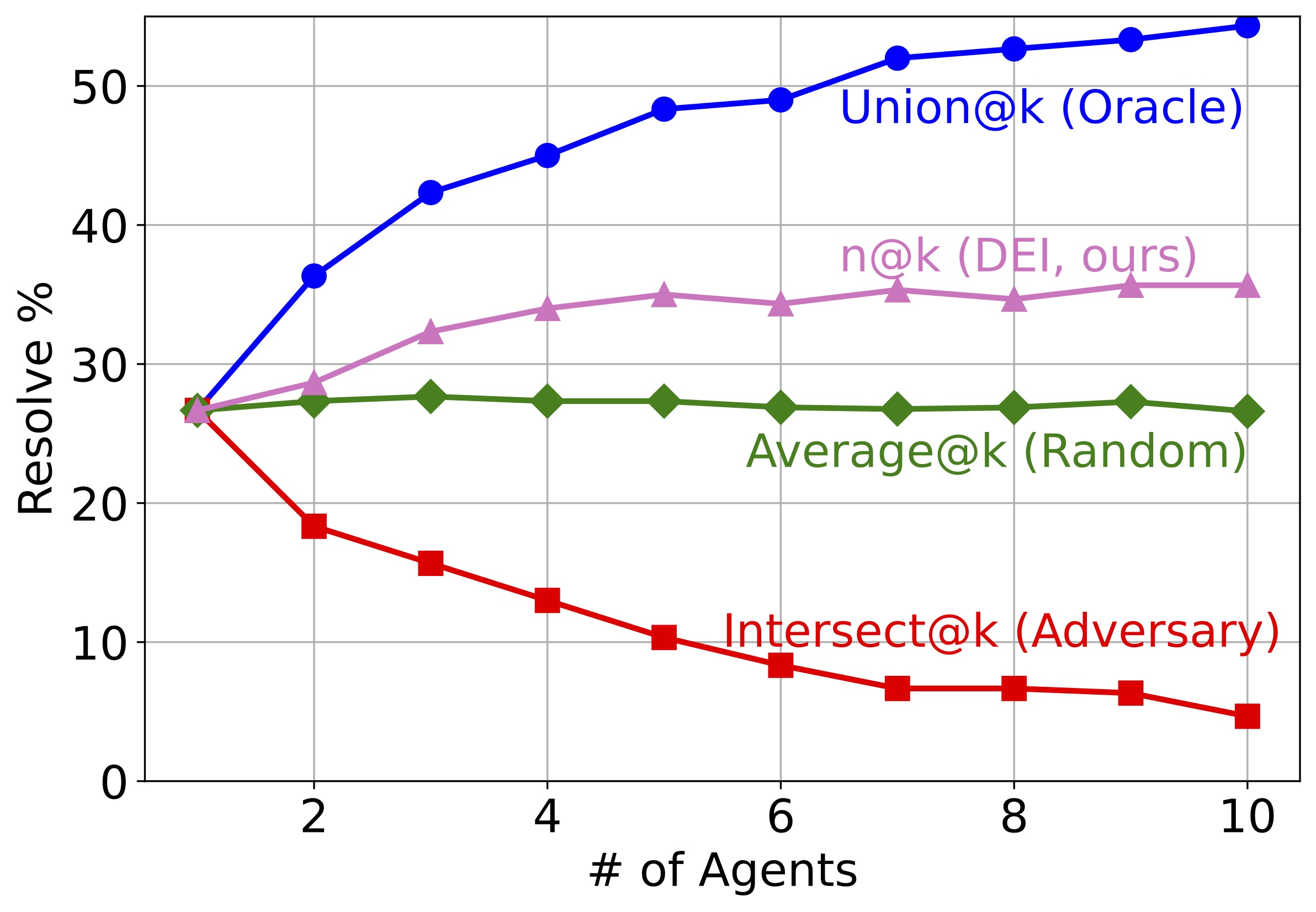
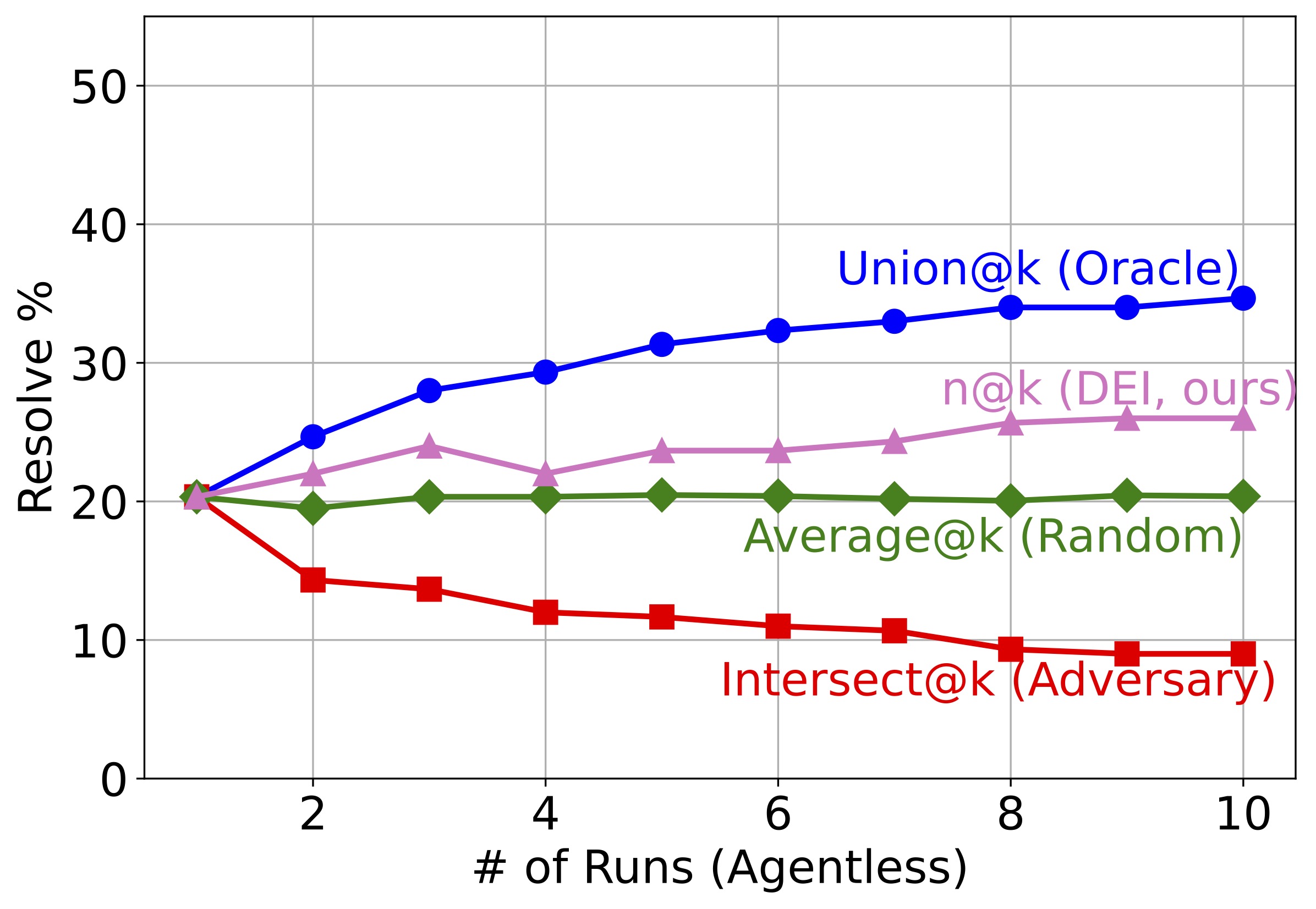
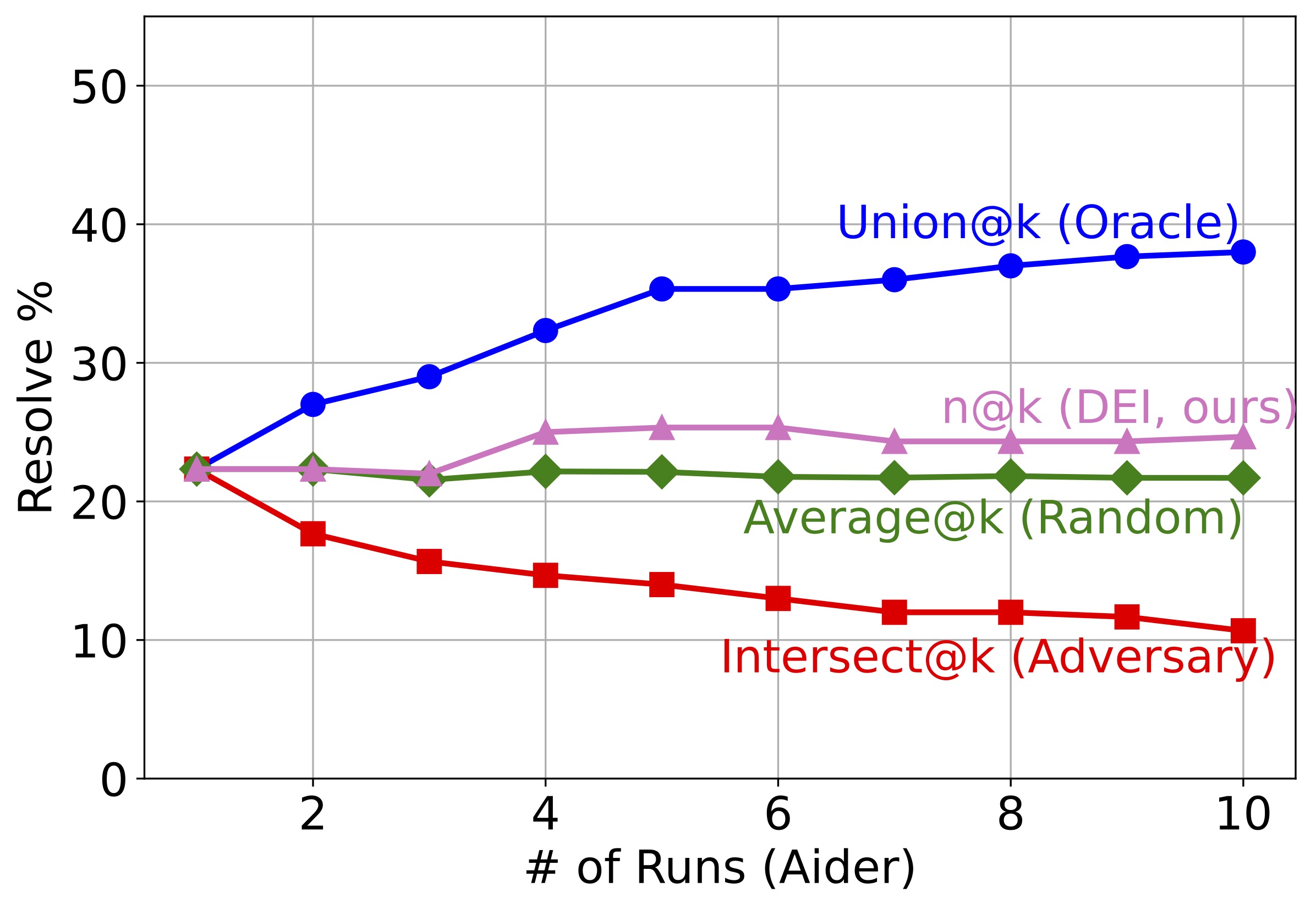
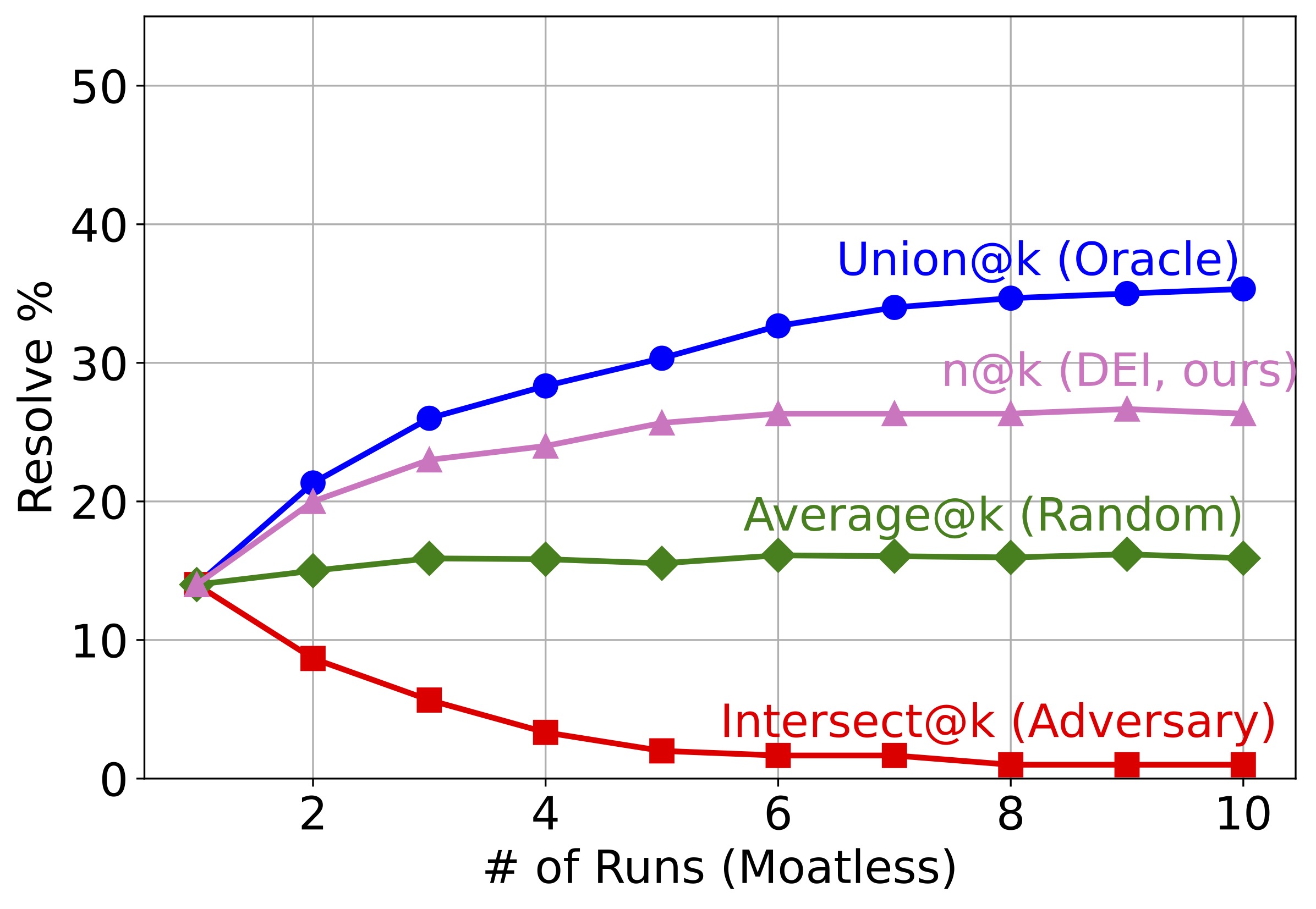
Figure 3: How different metrics change as more candidate solutions are involved. In all 4 scenarios, there is a huge gap between Union@k and Average@k.
Evaluation Metrics
We use the same set of metrics for both intra- and inter-agent diversity as these metrics are defined for multiple candidate solutions without requiring them to come from the same candidate:
- Resolve rate: Measures how good a SWE agent is. It is defined as the percentage of issues resolved by the agent. We measure both single SWE agents and DEI with it to see how much DEI helps.
- Union@k: Measures the best case performance had the agents been perfectly consistent by counting the number of problems solved by any of the k solutions.
- Intersect@k: Measures the worst case performance by computing the number of problems solved by all k solutions.
- Average@k: Measures the average case performance by computing the average number of problems solved. It corresponds to the case of a random reward function that uniformly samples a candidate solution for each problem.
- n@k: Measures the performance of any reranking mechanism by computing the number of problems solved by k chosen submissions from a given set of samples.
Our research questions can be answered by the gaps between these metrics. Union@k - Intersect@ measures how diverse the agents are, while n@k - Average@k measures how much DEI helps in selecting the correct candidate from these agents. Note that the order -- in which different runs are added -- matters as k gets larger, especially when the k candidate solutions come from k different agents. In our experiments, we add candidate solutions from the single agent according to the order they are generated, while we add solutions from different agents in a fixed order.
How diverse are LLM-based SWE agents?
To answer this question, we report the "@k" metrics of 10 different agents and 10 runs of single agents in Figure 3. Several observations can be made about the results: SWE agents resolve very different sets of issues across agents and agent runs. Their full potential is far from fully released. In all four subfigures, the gap between Union@k and Average@k, as well as between Average@k and Intersect@k, is large. As k—the number of candidates—gets larger, the gap also gets larger. In fact, Union@k is always more than 50% larger than Average@k for k≥5. This indicates that current SWE agents are potentially capable of resolving a lot more issues, as long as we have a reranker that can tell which candidates are correct. Different agents resolve more distinct issues than different runs of a single agent. In other words, diversity does empower intelligence. The absolute/relative difference between Union@k and Average@k is much larger in the first subfigure than the following three subfigures. As k approaches 10, the distinct issues resolved are 2× the average number of issues resolved by a single agent in the group.
How much does DEI help?
We apply DEIBASE to the candidates in Figure 3 as they are added to the group. Our findings are:
DEIBASE helps in most cases. For most values of k in all subfigures, we observe a significant improvement of n@k over Average@k, indicating that DEIBASE selects correct candidates much better than a random baseline.
DEIBASE helps more when the candidates come from different agents. This finding resonates with the similar finding from research question one: Since candidates from multiple agents have a larger potential of improvement (Union@k - Average@k), the actual improvements created by DEIBASE (n@k - Average@k) are also larger. This suggests that given a limited budget of candidates, we should probably choose diversity of agents over multiple runs of the same agent.
As k gets larger, DEIBASE's improvement first increases and then plateaus. While larger k generally indicates higher n@k, the margin gets smaller and there are cases when an increase in k results in a slight drop in performance. This suggests that the current DEIBASE is not ideal for a large group of agents and there is still room for a better reranking mechanism.
Based on the lessons we summarize above, we propose three DEIBASE groups in which each candidate is from a different agent and no more than 5 candidates exist for each instance. DEIBASE-1 consists of the top 2 agents. DEIBASE-2 consists of 5 closed-source agents that have high performance on the leaderboard. DEIBASE-Open consists of 4 open-source agents so that we know future researchers can run the entire pipeline.
We also evaluate DEIBASE's performance on these groups in the leaderboard results table. All three DEIBASE instances outperform the best candidate in the group. Surprisingly, DEIBASE-Open shows a 7% increase in resolve rates and beats most of the closed-source systems.
This page is adapted from the template of Video Language Planning project website. We thank the authors for providing the template.